Make Movies is my (arguably) over-engineered home lab project for making family movie night more accessible for my less-than technical family members.
By the way, if you couldn't tell (lol just don't look at the appendages), I've been messing around with Stable Diffusion XL.
A disclaimer:
We currently subscribe to Netflix, Amazon Prime & Disney+, pay our TV license and will go to the cinema when there's something we want to watch. The legality of using this project is questionable but morally, we are happy to use it to consume niche & unavailable content or content that I already own on physical media but CBA to get out the loft.
"I'd like to watch this random movie that's not on Netflix"
-- Non technical family member
Me:
Surely this can be automated right?
There were some challenges.
The only place I would be comfortable running this app is my home network, so I am subject to the UK ISP firewall, which is likely to include all of the (relatively speaking) best torrent sites. So I am forced to tunnel connections through a VPN.
I first had a go at using a TOR proxy but found that services would often be using some sort of DDoS protection, which forces TOR exit traffic through a browser check. It's beyond the scope of this project to bypass this, so instead, I looked at proxying through a free tier VPN. For this I used a combination of a SOCKS5 proxy via Dante on top of OpenVPN and a service called Proton VPN.
I opted to run this in a container to simplify configuration i.e. I can tunnel all internet traffic out one container. For the convenience of tooling and health checks, I run this on Kubernetes. Here's the helm chart. You can install with.
Torrent services are unreliable, so to consume them live would mean:
The best option then would be to batch scrape all the data that I need to build this app. Luckily I don't even need to sift through HTML (JQuery selectors anyone?), as one site, yts.mx, even has a decent REST API.
We'll need somewhere to store the scraped data with app metadata e.g. whether we already have the movie in our library. There's quite a lot of data actually (in the order of 50k movies) and it needs to be both searchable and mutable in big batches (when scraping).
If I were running this app commercially, I'd need to consider scalability, availability and OLTP vs OLAP. I'd opt to store the data in a DBMS, preferably MongoDB as the data isn't that relational. Then since the MongoDB full text search is both deprecated and terrible, I'd keep a copy of key fields asynchronously maintained in ElasticSearch.
But since I'm running this at home and don't plan to scale it past a single instance, I opted for just keeping the data in memory 😱🤓! Searching can then be done within the app process, by whatever is the best natural language search algorithm on NuGet (and I think I tried them all). I keep it persistent with a background thread that queues up updates to a JSON file and blocks the app from quitting until it's caught up. Here's the implementation.
Honestly, I reckon we can apply this YAGNI practise to scalability in more places than we realise. The cost of maintaining the infrastructure, team and licenses to do this "right" is not insignificant.
It takes quite a few moving parts.
TLDR; scraped movies are searchable and downloadable via the UI. Once downloaded, they are available to watch via Jellyfin.
Everything needed to run this project is available on GitHub.
In a sanity saving measure, I have opted to deploy most of the services on systemd.
This was actually more simpler than I thought it would be and the .NET bit even supports Type=notify via Microsoft.Extensions.Hosting.Systemd.
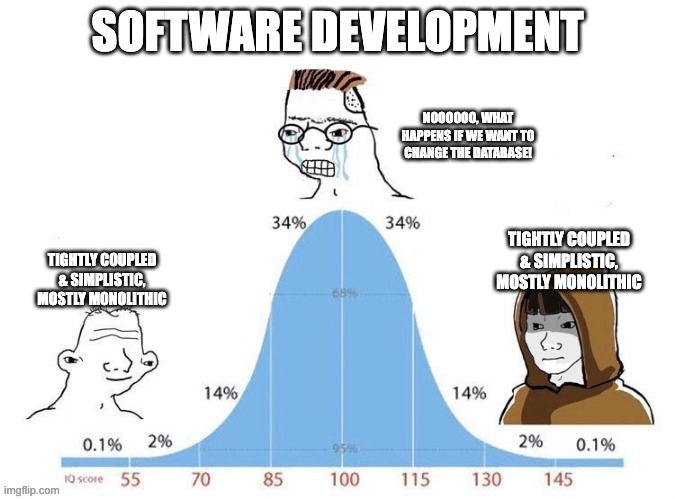
This could easily have been a massive project spanning multiple microservices, complex messaging, even more complex DBMS, ridiculously complex search engine and all deployed via some horribly complex helm chart.
Trust me, I tried it.
But after some fun learning all this stuff and some immense satisfaction watching it deploy to k8s with a single command, I had many issues that were much more painful to fix than a project 'for fun' should present. Then I had some nasty breaking changes in major version updates. I'd already blown way past any time I would have saved by using this project so I'd had enough.
I took the approach of stripping it back to an MVP and minimizing dependencies. E.g. I used to do scraping asynchronously over a MassTransit bus, now I just lock on a Mutex in a single service. This has resulted in a system that, yes, wouldn't scale to thousands of concurrent users, would be a bit of a pain to decouple in places and is mostly void of technical showcase but that ... works.
Honestly, I am proud of it for it's simplicity. I have been on the path to simplistic solutions to complex problems for years now but this experience has been yet another confirmation that (at least) starting with simplicity is fundamental to successful projects.